场景介绍
在政企采购、基建工程、教育医疗等领域,招投标是极为常见的业务流程。而每一份招标公告、投标文件、结果公示背后,都是一套格式不一、结构复杂、语义高度专业化的文本材料。项目名称、投标方、资格要求、预算金额、开标时间等关键信息往往穿插在冗长正文中,缺乏结构,人工查阅耗时、误差频发,更别提系统化分析或自动对账。 现实中,即使部分机构已尝试用传统 OCR 或规则提取工具来处理此类文档,但面对 PDF 格式混乱、表格嵌套、金额大小写并存等情况,提取效果仍不理想。数据不准、字段缺失、表格识别错误等问题频繁出现,最终还是得依赖人工去二次校验。尤其当处理的公告数量成百上千时,人力成本与时间成本急剧上升。 在这样的背景下,利用具备自然语言理解能力的大语言模型,构建一套能自动抽取招投标关键字段的通用方案,成为行业急需解决的问题。这不仅关乎效率提升,更是组织实现“招投标数据资产化”的前提条件。业务需求
从实际业务出发,企业或政府单位的目标很清晰:他们不是需要“看起来很智能”的技术,而是能真正减轻人力负担、提高准确率、提升处理速度的实用工具。 第一,必须能适配复杂格式。现实中的招投标文件来源多样,PDF、Word、网页、甚至扫描件都有可能出现。系统必须有能力处理这些不同格式,并从中提取结构化数据,不能因为格式复杂就放弃识别。 第二,系统要“懂语境”。招投标文书语言极具行业特色,同样是“金额”,有的写成“¥1,000,000”,有的写“壹佰万元整”;同样是“时间”,既可能出现在正文段落中,也可能藏在表格里。若没有上下文理解和对领域语言的适配能力,提取出的结果往往前后矛盾、缺乏价值。 第三,处理量大、时间紧是常态。大型平台一周可能需处理上千份公告,传统逐条人工录入根本不现实。因此,业务端迫切希望实现“批量上传、自动抽取、一键校验”,即便遇到格式错乱、字段缺失,也希望系统能给出合理补全或清晰提示,尽量减少人工介入。 最后,数据质量是底线。哪怕是自动化系统输出的结果,也必须可追溯、可校验。是否符合格式?时间逻辑是否成立?金额字段有没有异常?一旦进入财务、合规、系统对接环节,数据容不得含糊。这意味着系统还需具备后处理、格式统一、完整性校验等能力,以保障全流程的可用性和可信度。解决方案
一、方案框架
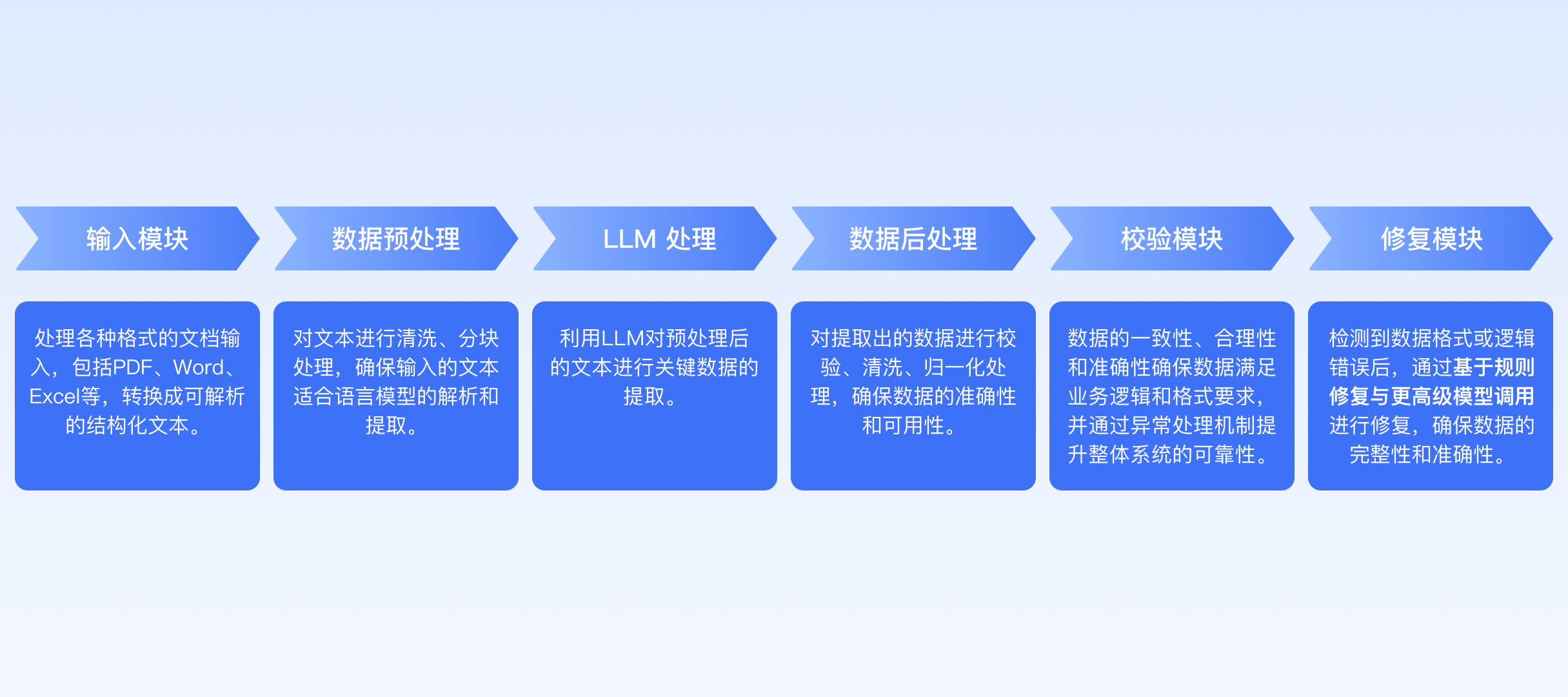
二、方案详情
输入模块设计
用于处理各种格式的文档输入,包括 PDF、Word、Excel、网页等,转换成可解析的结构化文本。- 多种文件格式支持:
- 需要支持从多种格式(PDF、Word、Excel、TXT 等)中提取文本。对于图片,可以借助 OCR 工具进行文本提取。
- 网页可以使用网页爬虫工具(如
Scrapy、BeautifulSoup、Selenium)抓取网页中的文本和表格数据。通过解析 HTML 的 DOM 结构,提取目标数据。(平台暂无工具)
- 参考代码
预处理模块设计
预处理模块的设计是整个数据处理流程的基础,直接影响到大语言模型后续处理的效果。通过文本清洗、文本规范化、分段分块、表格解析、上下文维护等功能,预处理模块能够将复杂的、多格式的数据源处理成统一、规范的输入数据,确保数据在转换过程中不失真,并为后续模型处理提供高质量的输入。数据的语义、结构以及相关性得以保留,特别是在处理复杂的文档结构、特殊符号、嵌套表格等数据。- 去除噪音信息:常见的噪音信息包括页眉、页脚、版权声明等,这些信息对关键数据提取无关紧要,可以在预处理时过滤掉。
- 规范化文本:处理文本中的特殊符号、空白字符、异常换行等问题,确保输入给模型的文本格式整洁。
- 日期格式统一:文档中可能会有多种日期表示方式,例如”2024 年 10 月 10 日”、“10/10/2024”、“10-Oct-2024”。需要通过正则表达式或日期识别工具将所有的日期格式统一转换为标准的 ISO 格式(如”YYYY-MM-DD”)。
- 方法:使用正则表达式匹配不同格式的日期,并将其标准化。例如:
- 参考代码
- 货币与金额格式化:货币和金额在招投标文件中非常常见,可能以不同的符号、单位或表示方法出现。例如:“$1,000”、“1000 美元”、“壹仟元整”。需要统一这些金额表示,确保货币单位和金额数字的格式标准化。
- 方法:通过正则表达式匹配货币符号或中文大写金额,并转换为标准形式。例如将”壹仟元”转换为”1000 CNY”,或将”$1,000”转换为”1000 USD”。
- 特殊符号处理:招投标文件中可能有特殊符号(如版权符号、数学符号、货币符号等),这些符号如果不加处理,可能在后续的 模型输入中失去原意或导致模型误解。因此,预处理模块需要对这些符号进行规范化处理。
- 表格数据处理:表格提取工具:对于 PDF 或 Word 文档中的表格,可以使用表格解析工具(如
pdfplumber或python-docx)提取表格的结构和数据。提取后的表格数据可以转化为 CSV 或 JSON 格式,方便后续处理。 - 合并单元格处理:如果表格包含合并单元格,预处理模块需要将合并单元格的数据平铺展开,确保每个单元格都包含完整的信息。例如,将合并的表头信息扩展到所有相应列的单元格中。
- 方法:表格数据的结构化转换时,可以转换为 Markdown 和 HTML 格式能很好地保留表格的结构,并方便 LLM 理解。在实践中,建议使用 HTML 表示复杂表格,例如:
LLM处理模块
在使用大语言模型(LLM,如 GPT)对预处理后的文本进行关键数据提取时,Prompt 工程是方案的核心。Prompt 工程的目标是设计合理的提示词,以最大化 LLM 的性能,从复杂的文本中准确、有效地提取出关键信息。 Prompt 策略 策略 01:明确的待处理内容指引 在构建 Prompt 时,明确告诉模型它需要处理的内容是关键步骤之一。应清晰地定义需要处理的文本,并使用标记将其框起来。例如:数据后处理模块
在完成关键数据提取之后,为确保输出的数据能够被系统正确识别和使用,后处理步骤至关重要。数据后处理包括 JSON 格式标准化 和 数据格式化 两个部分,分别解决数据结构的完整性问题和数据内容的准确性问题。 JSON 格式标准化 在使用大语言模型提取数据时,生成的 JSON 格式可能出现结构问题、不正确的语法、特殊字符等问题,导致数据无法正确解析。因此,需要通过 JSON 格式化工具对提取出的 JSON 数据进行标准化处理。使用指南 参考代码- 日期格式:所有日期和时间字段都应格式化为标准的 14 位日期时间格式:
YYYYMMDDHHMMSS。这可以确保时间字段在不同系统中具有一致的解析方式。 - 金额格式:金额字段应保留原单位(如元、万元),并且格式化为无空格、无额外字符的数值形式(如
500000元),以便在后续财务分析或报告生成中能够准确使用。 - 文本字段格式化:对文本字段中的特殊字符(如换行符、双引号)进行处理,确保文本内容不会破坏 JSON 的语法结构。比如,将双引号转义处理,或者移除无意义的换行符和空格。
数据校验模块
校验模块是数据后处理过程中至关重要的一环。其作用是对最终的数据进行进一步的校验,确保数据的完整性、准确性和一致性。校验模块可以自动检测格式错误、逻辑冲突、缺失值等问题,并提供修复或警报机制。 格式校验 确保所有数据符合预期的格式标准,例如日期、金额、电话号码等字段的格式是否正确。 如:检查金额字段是否包含正确的货币单位,并确保数值的表示形式规范。- 参考代码
- 校验方法:比较投标截止时间和开标时间,如果投标截止时间晚于开标时间,则返回错误。
- 参考代码
- 金额校验:采购预算金额不能小于中标金额。校验预算和中标金额,确保金额逻辑合理。
- 校验方法:如果中标金额高于预算金额,则返回警报。
- 必填字段检查:对于某些字段,如“项目名称”、“项目编号”、“投标截止时间”,应强制要求填写,若缺失则进行标记或补全。
- 校验方法:通过预定义的字段列表检查 JSON 输出中是否包含所有必填字段。
- 自动填充默认值:如果某个字段为空或缺失,可以自动填充默认值“无”。
- 参考代码
- 项目编号一致性:项目编号在不同字段中应当相同,如出现在多个部分的项目编号不能出现不一致的情况。
- 校验方法:检查项目编号是否一致,如果发现不同编号,则触发警报。
- 日期一致性:多个时间字段中如果是同一事件(如开始时间和结束时间在不同部分中重复出现),应确保其一致。
- 参考代码
数据修复模块
检测到数据格式或逻辑错误后,通过基于规则修复与更高级模型调用进行修复,确保数据的完整性和准确性。通过修复模块,能够自动纠正常见的错误,如格式错误、缺失数据或逻辑冲突,避免手动修正,提高效率。 基于规则的自动修复 在大部分情况下,错误可以通过预定义的规则和算法进行自动修复。此步骤作为第一层处理机制,针对格式错误、简单的逻辑冲突、特殊字符处理等问题进行修正。- 格式修正:通过正则表达式或预定义算法修复日期、金额、电话号码等格式错误。
- 逻辑修正:检查和修复时间顺序、金额逻辑等问题。对投标截止时间、开标时间、金额关系进行简单调整。
- 数据填补:自动填补缺失字段,使用“无”或从其他字段推导合理值。
- 处理复杂业务逻辑:当多个数据字段之间存在复杂的依赖关系时,普通的规则引擎可能无法有效处理,例如合同条款中的复杂逻辑冲突,此时可以利用高级模型的上下文理解能力进行推理和调整。
- 识别与处理领域特定信息:高级模型擅长理解和处理特定领域的复杂术语、语境或结构不明的信息,如行业专用术语、合同中的特殊条款等。
数据处理神器-Batch API
Batch API 适用于无需即时反馈并需使用大模型处理大量请求的场景。通过 Batch API,开发者可以通过文件提交大量任务,且价格降低50%(GLM-4-Flash免费)、无并发限制。Batch API 使用指南
单次处理千万级数据
限时特惠资源包
GLM-4-AIR:卓越性能,性价比极高,高效处理海量数据,立即抢购:
- 1000万 GLM-4-AIR 推理资源包(3 个月) :立即购买,限时特惠仅需3元
- 5000 万 Embedding-3 3 折尝鲜包(3 个月) :立即购买,限时特惠仅需 7.5 元