概览
GLM-4.5V 是智谱新一代基于 MOE 架构的视觉推理模型,以 106B 的总参数量和 12B 激活参数量,在各类基准测试中达到全球同级别开源多模态模型 SOTA,涵盖图像、视频、文档理解及 GUI 任务等常见任务。
定位
旗舰视觉推理
输入模态
视频、图像、文本、文件
输出模态
文本
上下文窗口
64K
GLM-4.5V 价格详情请前往价格界面
能力支持
深度思考
启用深度思考模式,提供更深层次的推理分析
视觉理解
强大的视觉理解能力,支持图片,视频,文件
流式输出
支持实时流式响应,提升用户交互体验
上下文缓存
智能缓存机制,优化长对话性能
推荐场景
前端复刻
前端复刻
支持将网页截图或完整浏览录屏输入模型,自动解析布局与交互逻辑,高精度还原页面元素与二级页面结构,生成可交互的 HTML 代码,便于直接使用或二次优化。
Grounding
Grounding
可根据文本描述精准定位指定人物或物体,支持按外貌、衣着等多条件组合筛选。适用于安检、质检、内容审核、遥感监测等实业场景,定位精度高。
GUI Agent
GUI Agent
识别并理解屏幕画面,执行点击、滑动等操作指令,精准完成如 PPT 修改、Word 编辑等任务,全程自动化,适用于各类办公场景,为智能体操作任务提供可靠支持。
复杂长文档解读
复杂长文档解读
支持对长文档进行深度解析,处理文本、表格、图形等多模态内容,可总结、翻译、提取关键信息,并在原有观点基础上提出新见解,适用于研报分析、科研、教育等专业场景。
图像识别与推理
图像识别与推理
结合强推理能力与丰富世界知识,在无需搜索的情况下推断图像背景信息。支持将图表、曲线等内容转为结构化数据,精确还原内容与布局,适用于无电子版表格的快速数字化处理,避免手动录入的繁琐与错误。
视频理解
视频理解
支持解析长时视频内容,精准识别并推理视频中的时间线、人物关系、事件发展及因果逻辑,适用于安防监控、影视内容分析、舆情事件追踪等领域,实现高效的视频信息抽取与洞察。
学科解题
学科解题
具备图文感知、知识储备与推理能力,能够解决复杂的图文结合题目,适用于 K12 教育场景中的解题和讲解需求。
使用资源
体验中心:快速测试模型在业务场景上的效果接口文档:API 调用方式
详细介绍
1
开源多模态 SOTA
GLM-4.5V 基于智谱新一代旗舰 GLM-4.5-Air,延续 GLM-4.1V-Thinking 技术路线进行迭代升级,在 41 个公开视觉多模态榜单中综合效果达到同级别开源模型 SOTA 性能,涵盖图像、视频、文档理解及 GUI 任务等常见任务。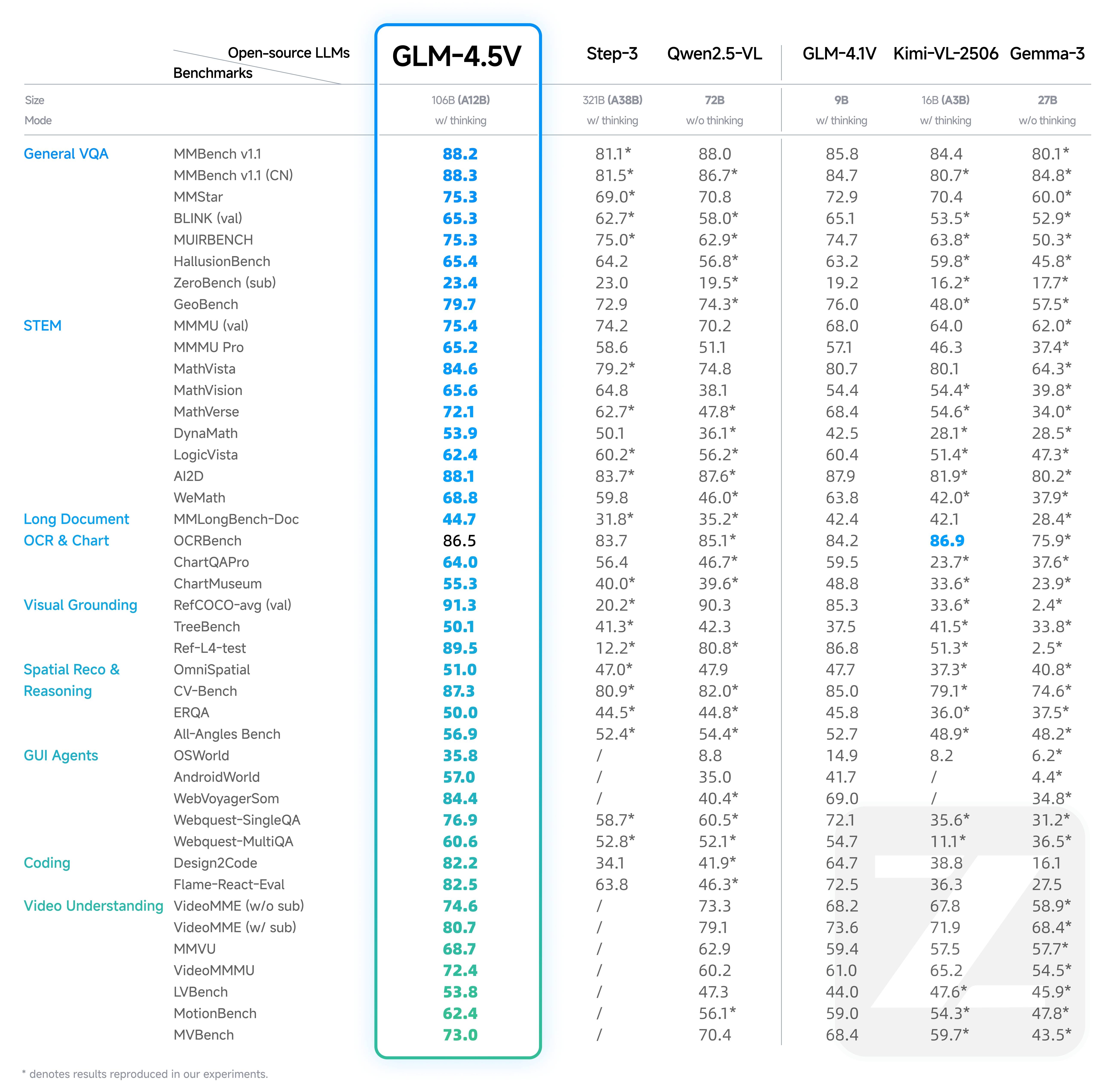
2
支持 Thinking 和 Non-Thinking
GLM-4.5V 新增“思考模式”开关,用户可在快速响应与深度推理之间自由切换,根据任务需求灵活平衡处理速度与输出质量。
应用示例
- 视频前端复刻
- 图片翻译
- GUI Agent
- 图表转换
- 学科解题
- 文档解读
- Grounding
输入
prompt:帮我生成这个video中所展示的html code ,需要包含视频中的点击、跳转、交互等
输出
代码略.渲染后的网页截图:
调用示例
基础与流式
- cURL
- Python
- Java
- Python(旧)
基础调用流式调用
多模态理解
不支持同时理解文件、视频和图像。
- cURL
- Python
- Java
图片理解视频理解文件理解
用户并发权益
API 调用会受到速率限制,当前我们限制的维度是请求并发数量(在途请求任务数量)。不同等级的用户并发保障如下。
| 模型版本 | V0 | V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 |
|---|---|---|---|---|---|---|---|---|---|
| GLM-4.5V | 10 | 30 | 50 | 80 | 100 | 120 | 150 | 150 | 150 |