“上下文增强”检索旨在通过重建每个知识碎片的完整上下文,让AI能够像人类专家一样,不仅“读懂”文字,更能“理解”其背后的深层含义与结构,从而显著提升您知识问答系统的准确率和用户满意度。
上下文增强技术报告
随着大语言模型(LLM)的浪潮席卷各行各业,我们看到越来越多的企业正在使用我们的知识库产品,结合RAG技术构建智能问答、客服、和文档查询系统。 然而,我们也敏锐地洞察到,当您的知识库变得庞大、文档变得冗长复杂时,传统的RAG技术开始显现出它的局限性。您可能也曾遇到过这些令人困扰的场景:- 问了一个很具体的问题,系统却返回了风马牛不相及的段落。
- 明明知道答案就在某份报告的第三章,但系统就是找不到。
- 模型回答经常“张冠李戴”,错误地理解了专有名词或代词的指代。
1. 挑战:传统RAG检索在复杂知识库中面临的三大难题
在深入了解我们的解决方案之前,让我们先清晰地定义传统RAG技术遇到的具体挑战:挑战一:上下文缺失导致“语义漂移”
- 问题描述:当一篇长文档(如研究报告、法律合同)被切分成小段落后,每个段落都失去了它的“位置感”。例如,“该系统性能提升了30%”这个段落,如果脱离了“第二季度财报-核心产品线表现”这一章节标题,AI将无法知道“该系统”具体指代什么,也无法理解这个性能提升是在哪个时间背景下发生的。
- 用户体感:模型回答模糊不清,甚至出现事实性错误。
挑战二:关键元信息丢失导致“检索失败”
- 问题描述:用户的提问方式是多样的。他们可能会问“2023 年用户增长报告里关于新用户的部分怎么说?”,问题中包含了“文档名称”和“章节”等关键信息。但如果这些信息恰好没有出现在被切分的段落文本内,传统的检索方法就无法命中正确答案。
- 用户体感:系统频繁反馈“找不到相关信息”,尽管知识库中明明存在答案。
挑战三:单一检索模式的“能力缺口”
- 问题描述:目前主流的检索方式有两种,但都存在短板:
- 向量检索(Semantic Search):擅长理解语义和概念,但对于精确的关键词、产品型号、专有名词(如 Model-X7 )的匹配能力较弱。
- 关键词检索(Keyword Search,如 BM25):能精准匹配关键词,但无法理解同义词、上下位概念或整体主题。例如,它无法理解“车辆安全性能”和“碰撞测试表现”之间的强关联。
- 用户体感:检索结果要么“抓不住重点”,要么“过于死板”。
2. 我们的解决方案:上下文增强
上下文增强功能通过自动化流程,为您的每一个知识切片生成一份信息丰富的“上下文摘要卡片”,并将其与原始文本“绑定”,共同参与检索。 核心理念:为知识切片“恢复记忆” 想象一下,我们不再给AI提供孤立的段落,而是为每个段落都附上一张卡片,上面清晰地写着: “这段内容摘自《2024 年第一季度市场分析报告》的‘竞品动态’章节,主要讨论了‘A公司’发布的新产品。其中提到的‘它’指的是A公司的新品。” 这张“卡片”就是我们自动生成的上下文描述(Contextual Text)。它通常包含:- 来源信息:所属的文档名称、章节标题、列表序号等。
- 主题概括:对该切片核心内容的精炼总结。
- 关键实体:提取出的核心人物、产品、指标、时间等。
- 歧义消除:明确代词(如“它”、“该公司”)的具体指向。
- 风格保持:生成的描述语言与原文风格保持一致,确保语义连贯。
一个直观的例子:
通过这种方式,即使原始切片前言不搭后语,其增强后的整体也包含了丰富的语义上下文,无论是语义理解还是关键匹配都能精准命中。
3. 技术实现:三重保障,确保检索质量
为了将“上下文增强”的效果发挥到极致,我们在后端采用了稳健且高效的三重技术架构:第一重:双索引架构(Dual-Index Structure)
我们同时为您的知识库构建两种类型的索引,各司其职:- 向量索引(Vector DB):负责语义理解。我们将“原始文本 + 上下文描述”整体进行向量化,使其能够在高维空间中捕捉复杂的语义关系。当用户提出一个概念性的问题时,它能迅速找到含义最相近的内容。
- 文本倒排索引(Elasticsearch BM25):负责精确匹配。它对所有文本进行分词,能快速定位包含特定关键词、年份、产品型号的段落,弥补向量检索在细节上的不足。
第二重:加权融合排序(Weighted RRF Fusion)与重排模型
当用户发起一次查询时,我们会同时向两个索引“提问”,并各自获得一份候选结果列表。随后,通过加权RRF融合算法或重排模型,我们将两份列表进行合并与重排。- 优势:这种混合检索策略确保了结果既有语义上的相关性,又不失关键词的精确性,达到“1+1 > 2”的效果。
- 灵活性:您还可以根据自身业务需求,调整向量检索和关键词检索的权重,实现最优的排序策略。
第三重:高效缓存与处理
我们深知在企业级应用中,效率和成本至关重要。- 生成效率:上下文的生成过程经过高度优化,确保在知识库索引阶段的耗时可控。
- 缓存机制:对于已处理的文档,系统会智能利用缓存,避免重复计算,进一步提升大规模知识库的处理效率,并大幅降低 token 消耗成本。
4. 您是否应该启用“上下文增强”?
我们建议在以下场景中,优先启用此功能,您将获得立竿见影的效果:场景一:拥有大量长篇、结构化文档
如果您的知识库包含大量研究报告、技术手册、财务报表、保险合同等,这些文档结构复杂、章节分明、内容存在前后引用关系。场景二:需要进行深度、细粒度的问答
如果您的用户经常提出需要结合上下文才能回答的“情景类”问题,例如:“对照去年,我们今年的研发投入主要用在了哪些新项目上?”场景三:对问答的准确性有极高要求
在智能客服、技术支持、企业内训等场景,错误的回答可能导致用户流失或内部决策失误。上下文增强能最大程度减少AI“幻觉”和事实错误。不一定需要的情况:
如果您的知识库主要是由大量简短、独立的问答对(FAQ)、或独立的条文条款组成,每个问答或条款本身已经包含了完整的上下文,那么传统RAG方法可能已经足够,启用此功能的收益相对有限。5. 性能评测
5.1 缓存命中率
经过测试,我们的缓存命中率普遍在80%以上,平均命中率在85%以上。这将使您可以使用极少的token消耗来处理大文档。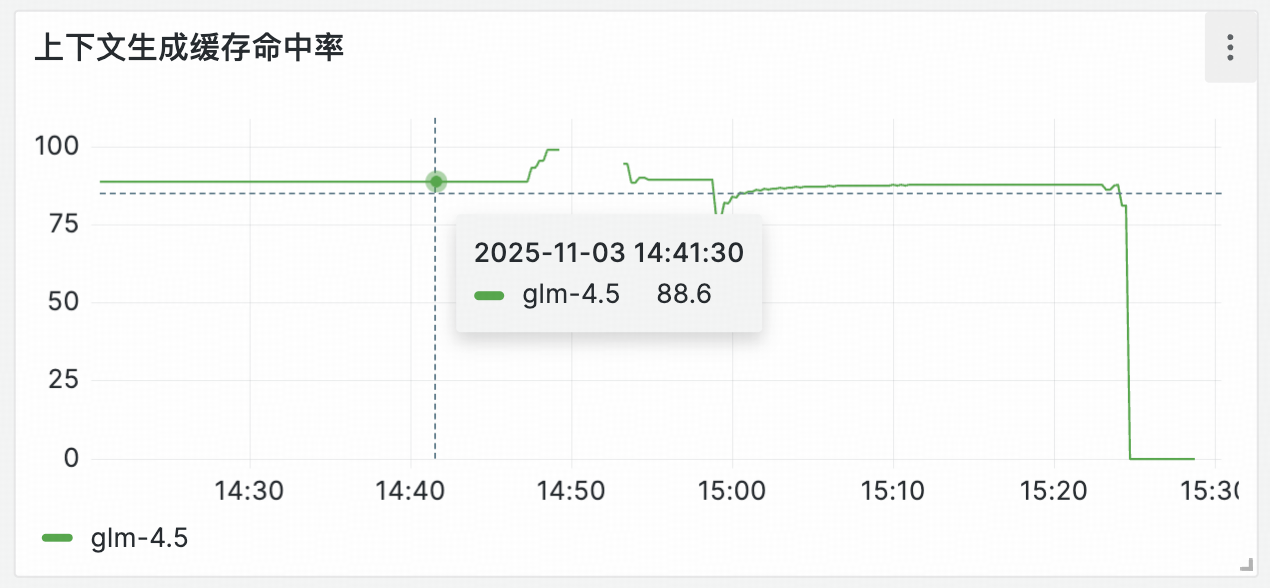
5.2 生成耗时
在我们的测试中,平均每个文档大约需要100 秒左右的处理时间,超长文档(切片数量超过200 个)平均耗时在300 秒左右。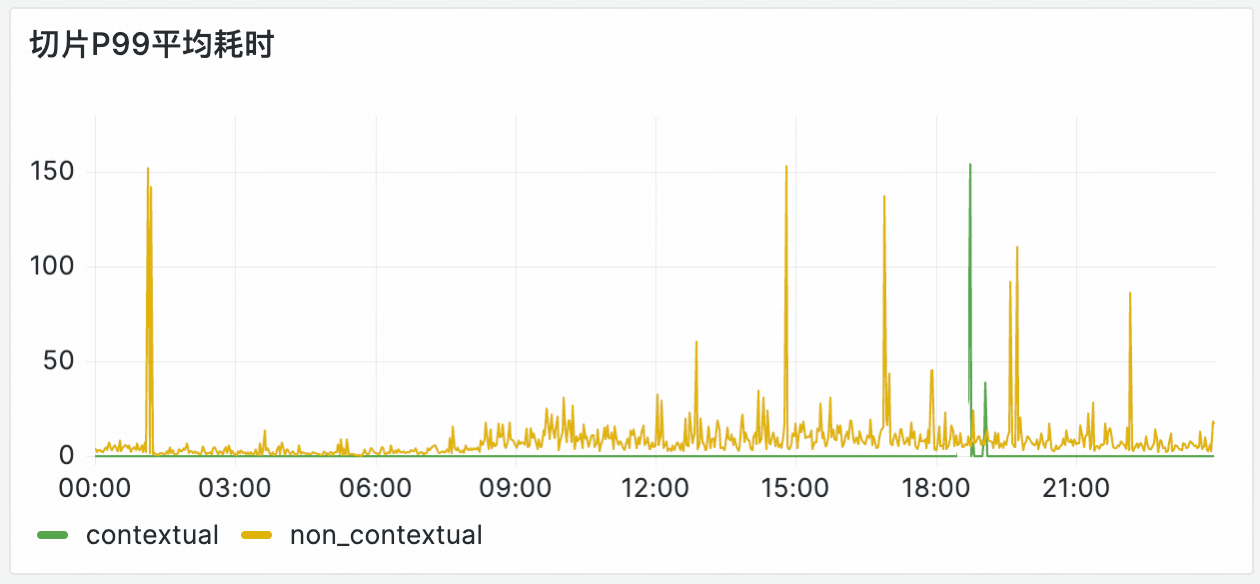
5.3 效果评测
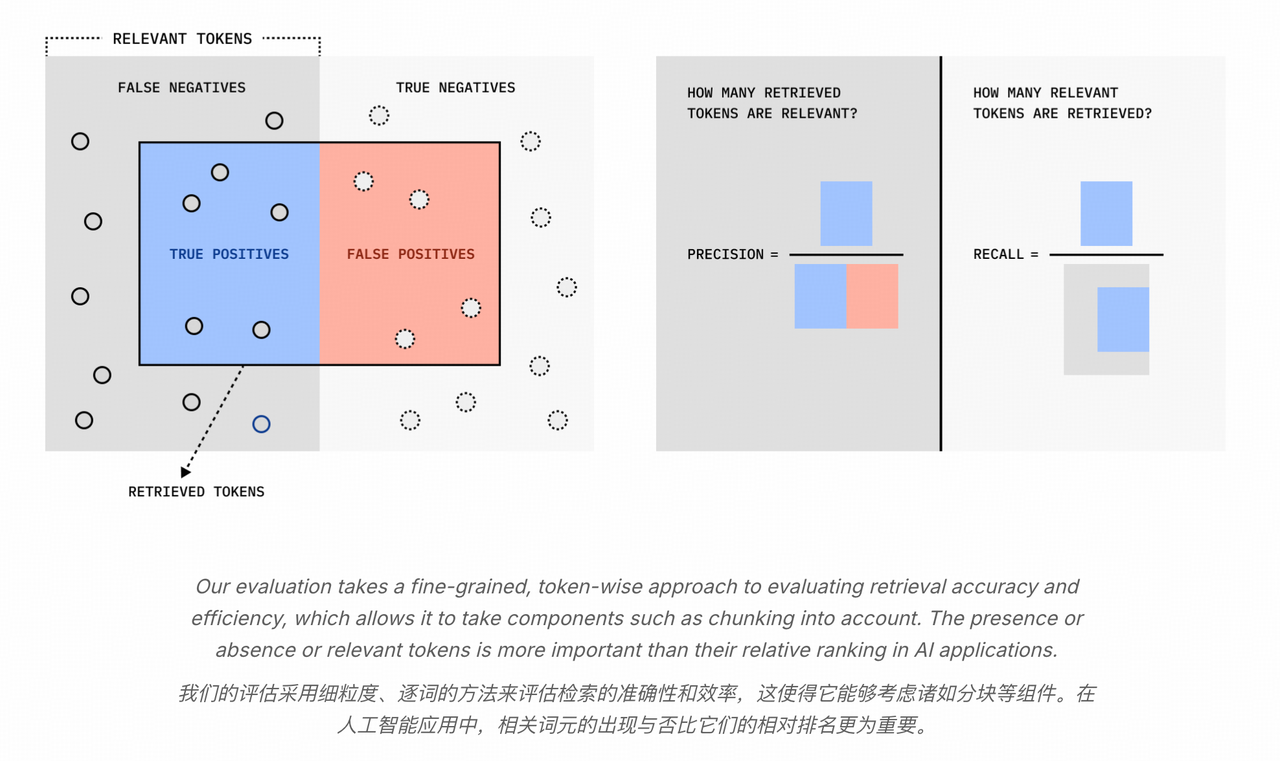 由于正确切片和实际切片的之间的差异,我们无法直接判断切片是否召回,因此我们定义了一个token 级别的召回率,用于判断切片是否正确召回。当token召回率大于一定阈值(通常是0.8)时,我们将该切片视为正确召回。
由于正确切片和实际切片的之间的差异,我们无法直接判断切片是否召回,因此我们定义了一个token 级别的召回率,用于判断切片是否正确召回。当token召回率大于一定阈值(通常是0.8)时,我们将该切片视为正确召回。
- 检索召回率(Recall):相关片段被成功召回的比例,衡量系统覆盖相关内容的能力。
- 检索精准率(Precision):检索片段中命中相关片段的比例,衡量系统返回结果的纯度。
- F1 Score:Precision 与 Recall 的调和平均,用于在两者存在权衡时提供一个综合评价指标,尤其适用于正负样本分布不均衡的检索与分类任务。
- 端到端语义一致性准确率(End-to-End Semantic Accuracy):模型基于检索结果生成的最终答案,与参考答案在语义层面的等价性或一致性比例。通常通过语义相似度模型、判别式评估器或人工标注判断,用于衡量完整 RAG 流程(检索 + 生成)的真实回答质量。
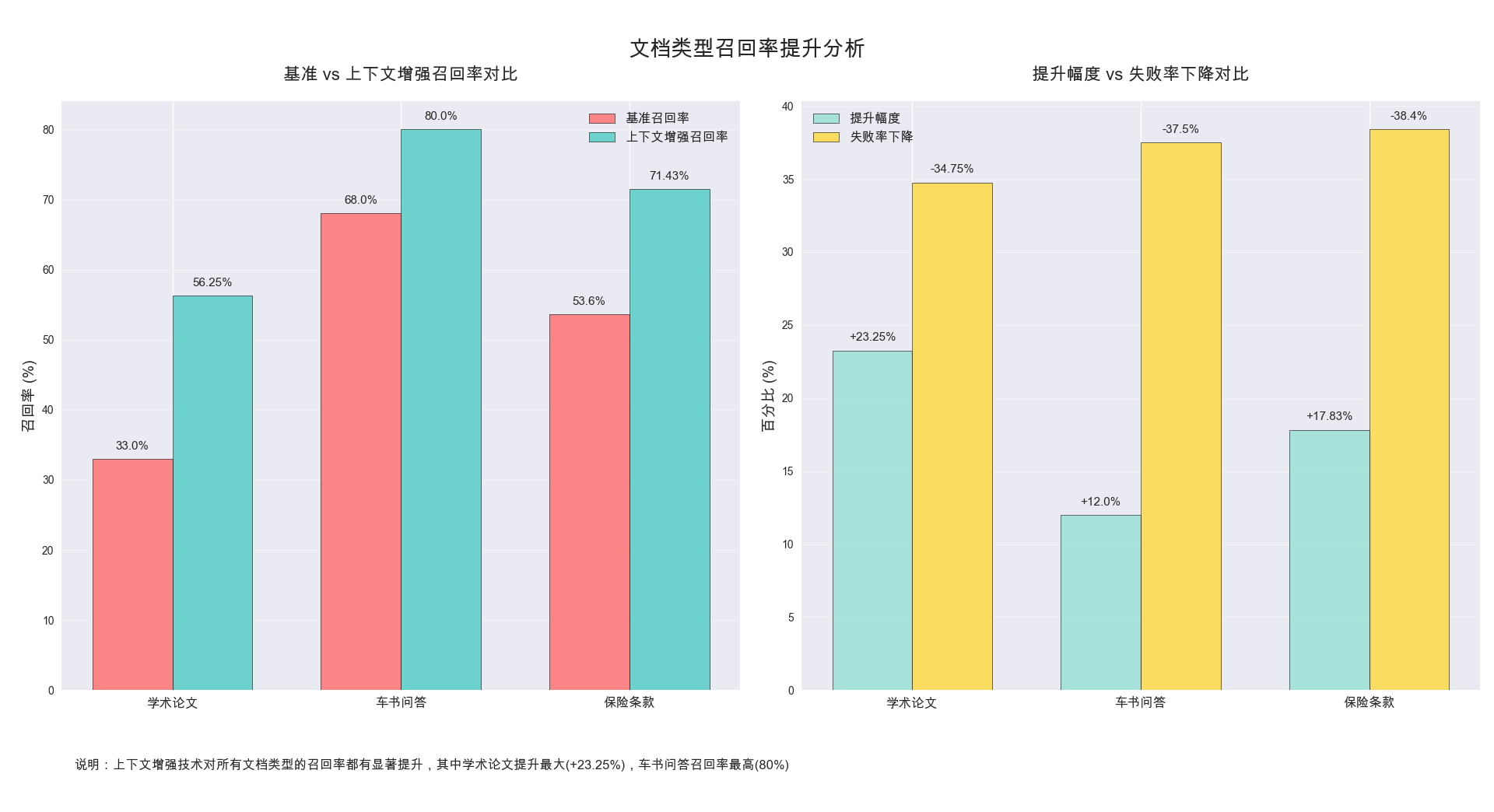 后续我们将会在更多评测集上进行评测,相关评测数据会更新到文档中来,并形成一个上下文增强的最佳实践。
后续我们将会在更多评测集上进行评测,相关评测数据会更新到文档中来,并形成一个上下文增强的最佳实践。